How to squeeze the maximum of RAG: How it works with AI

In the beginning was RAG, and RAG was with Knowledge, and RAG was Knowledge. Through RAG, all information was made accessible; without RAG, a query was answered completely. In RAG was the truth, and that truth became the light of artificial intelligence, shining in the darkness of uncertainty. And the models saw RAG, and they were enhanced.
No, just joking.
In the beginning, there was an idea to show our customers how RAG data sources work and stay secure, so they can see the real benefits of having up-to-date, reliable information that makes their projects run smoother. Curious? Read the article!

Table of contents
What is RAG?
How RAG works
Understanding your data better with retrieval augmented generation
Why is RAG important
Security and data privacy considerations
How RAG works in project management field: Easy Redmine
General recommendations for RAG
Easy AI with RAG: Practical use-cases for your projects, tasks and tickets
RAG sum-up
What is RAG?
RAG, or retrieval-augmented generation, enhances the functionality of large language models (LLMs) by integrating up-to-date external knowledge sources directly into the response generation process. By doing so, it empowers LLMs to deliver highly relevant and precise answers that extend far beyond their initial training data.
This approach transforms LLMs into dynamic tools capable of accessing the most current information, ensuring outputs that are both accurate and contextually aligned with evolving needs.
How RAG works
To help RAG work properly, you need to provide data from sources like APIs, databases, or document repositories that are transformed into vector formats and stored in a vector database, ready for quick retrieval.
RAG works through a simple and powerful process to deliver accurate and relevant responses:
- Relevancy search: When you ask a question, RAG searches the vector database to pull out the most relevant information for your query from external data sources.
- Prompt augmentation: The retrieved information is combined with your question to enhance the input for the large language model.
- Response generation: The LLM uses its training data along with the enhanced input to give you accurate, detailed, and context-aware answers.
Understanding your data better with retrieval augmented generation
Think of RAG as a super-smart friend who searches for the best answers, combines them with what they already know, and gives you clear and accurate responses.
Here’s how it all happens:
- Searching for information: Imagine you ask your friend a question. RAG works by first searching through various sources of information, like books or websites. It’s like your friend going to the library or browsing the internet to find the answer for you.
- Processing the information: Once it finds the relevant information, RAG combines it with what your friend already knows. This helps him create an answer that’s not only accurate but also easy to understand.
- Providing the answer: Finally, your friend uses all this information to give you an answer to your question. This makes his responses much more precise and up-to-date than if they relied solely on what he already knew.
By connecting to your existing data sources, RAG ensures that sensitive information stays protected through assigned permissions and centralised management. This means you get tailored, reliable answers while maintaining control over who can access what information in your organisation.
The result? More efficient project management and customer service, powered by AI that understands your unique business context.

Why is RAG important
RAG ensures AI stays accurate, up-to-date, and useful. Here’s how it improves reliability:
- Accuracy: With RAG, the risk of errors and misinformation (known as "hallucinations" in AI) is reduced because the model has access to verified data.
- Updates: RAG allows models to use the latest information, which is crucial in our fast-changing world.
- Applications: This technique is used in various applications, such as chatbots and virtual assistants, that need to provide accurate and relevant answers.
Security and data privacy considerations
As AI evolves, so do concerns about data security, especially with techniques like RAG. While RAG excels at integrating external knowledge sources for accurate outputs, its handling of sensitive data demands attention. This becomes particularly critical in light of cases like Samsung, where confidential information was inadvertently leaked through ChatGPT.
Samsung and data leakage from ChatGPT
In 2023, Samsung engineers used ChatGPT to assist with their work, but this led to a significant issue. Confidential information, including proprietary source code and internal meeting notes, was entered into the AI. OpenAI, ChatGPT’s provider, states that user input can be stored and used to improve the service, meaning Samsung’s sensitive data is now in OpenAI’s system.
To address this, Samsung paused the use of ChatGPT and similar AI tools by employees. The company is also working on internal safeguards and considering developing its own AI solution to prevent such incidents in the future.
While the technical aspects of RAG are well-explored, there is a lack of emphasis on the privacy and security implications of retrieving and processing sensitive or proprietary information, especially in enterprise settings.

Llama and OpenAI LLMs
Data protection by Llama
Anyway, Llama 3.3, the latest open-source large language model from Meta, incorporates several features to prevent content safety while offering impressive technical specifications.
At the forefront is Llama Guard 3, a highly sophisticated content moderation system that filters out sensitive or inappropriate material. Meanwhile, Code Shield works behind the scenes to eliminate insecure code suggestions, ensuring safer outputs for developers and end-users. To further minimize vulnerabilities, CyberSecEval 2 evaluates potential security risks in the model’s responses, prompting improvements where necessary.
Developers also benefit from the Responsible Use Guide provided by Meta, offering ethical guidelines to navigate complex use cases.
Technical specifications of Llama
Under the hood, Llama 3.3 offers different model sizes, including the flagship 405-billion-parameter model alongside smaller 8B and 70B variants. It’s trained on a dataset of over 15 trillion tokens, giving it a broad knowledge base. The model supports a context length of up to 128K tokens, allowing for more extensive and nuanced conversations.
Users can interact with Llama 3.3 in eight different languages, demonstrating its global reach. Architecturally, it follows a standard decoder-only transformer approach, but with careful optimizations that enhance stability and scalability. To further improve efficiency during inference, Llama 3.3 shifts from 16-bit (BF16) quantization to 8-bit (FP8).
This trimming of precision doesn’t compromise performance: the model remains competitive with leading closed-source systems like GPT-4 and Claude 3.5 Sonnet.
How RAG works in project management field: Easy Redmine
The Easy Software “RAG-enhanced GenAI” solution combines a vector‐database–powered retrieval layer with an LLM inference engine, wrapped in a prompt‐processing and guardrail workflow. Put simply, it mixes search/retrieval (“R”) with on‐the‐fly generation (“G”) to deliver context‐aware responses.
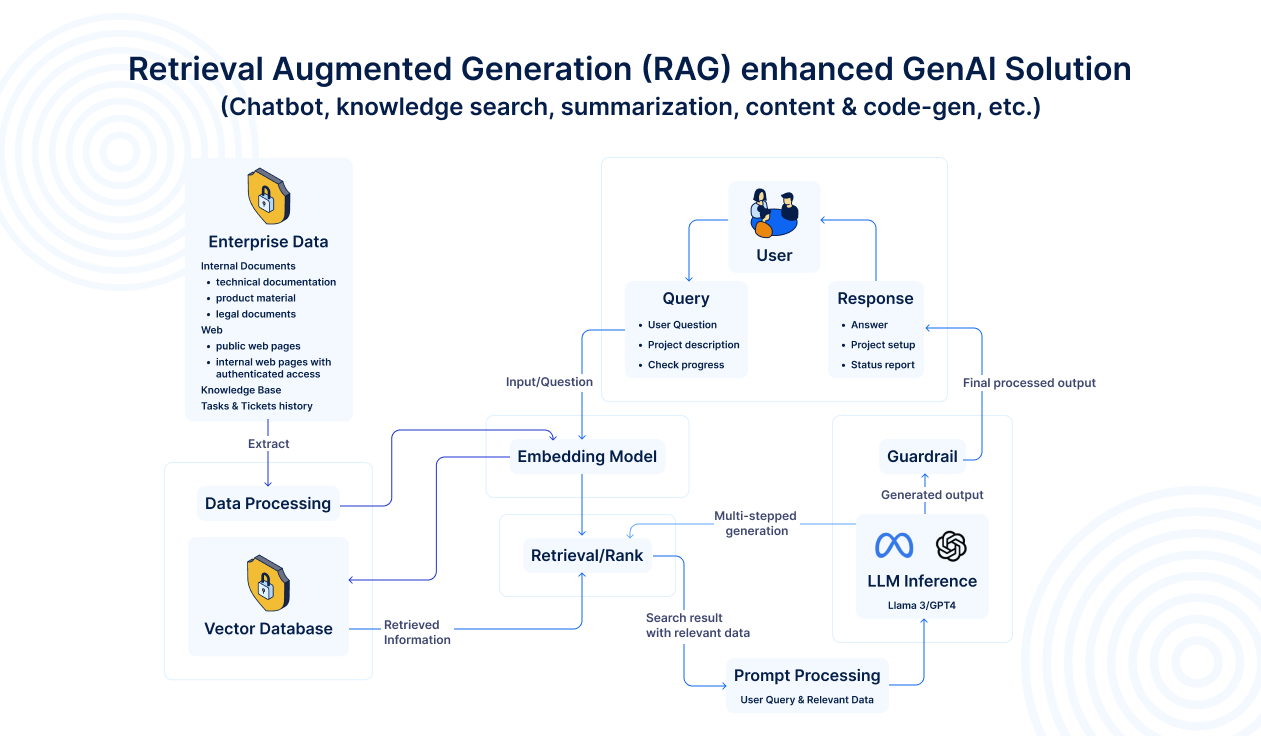
RAG architecture by Easy Software
Easy Redmine’s approach to RAG ensures unparalleled data security and control, thanks to its on-premises deployment option. This setup is the key reason why data leakage doesn’t occur.
In short, the open-source Llama model runs entirely on your own server, ensuring that no data is transmitted elsewhere. This guarantees that sensitive information remains within your infrastructure, completely inaccessible to external parties, providing peace of mind and robust protection against unauthorised access. Combined with comprehensive data sources like Knowledge Base articles, tasks, HelpDesk tickets, PDF file management, and website data indexing, Easy Redmine delivers a secure and adaptable RAG ecosystem.
General recommendations for RAG
Advancing RAG systems involves exploring integration, real-time updates, and user feedback to improve functionality and user experience.
Integration with multimodal data
The current literature primarily focuses on text-based data retrieval. Exploring how RAG can be extended to handle multimodal data—could enhance the versatility of LLMs in processing diverse information sources.
Real-time data retrieval
Discussions often centre on static datasets. Investigating methods for integrating real-time data streams into RAG systems would enable LLMs to provide up-to-date information, which is crucial for applications requiring current data.
In the case of Easy Redmine, when you upload a new Knowledge Base post, it is immediately added to the data sources for RAG, allowing users to access and use the information in real-time.
User feedback for continuous improvement
We strongly recommend incorporating a mechanism for user feedback into RAG systems to refine retrieval accuracy and response generation over time, which is essential for adaptive learning systems. For example, our Easy AI Assistants have emojis to rate the answer.
Easy AI with RAG: Practical use-cases for your projects, tasks and tickets
Want to know how we ensure accuracy in our AI responses? At Easy Redmine, we use RAG technology to provide you with precise, up-to-date information from trusted sources. Think of RAG as your personal research assistant who checks multiple verified documents before answering your questions.
When you interact with our AI features, such as Knowledge Assistant that helps with answering questions, providing real-time decision support, and generating actionable insights, RAG searches through our secure Knowledge Base to find relevant information. This technology helps maintain data security while delivering accurate responses based on your company's specific context and needs.
Easy AI, which also powers HelpDesk Assistant, uses RAG LLM to provide precise and context-aware responses by retrieving relevant information from your knowledge base. This ensures quick and accurate resolutions to customer queries while maintaining secure and efficient support workflows.
RAG sum-up
RAG is essential for advancing AI by integrating external knowledge sources into response generation, ensuring accurate and contextually relevant outputs. Protecting sensitive information while leveraging RAG ensures organisations can access up-to-date and precise information without compromising data integrity or privacy, making it a cornerstone of trustworthy and efficient AI systems.
In the case of Easy Redmine, RAG is a crucial technique for enhancing AI's intelligence and reliability, designed to deliver precise and high-quality answers by leveraging data directly from Knowledge Bases, issues, and other sources without manual searching. It powers Knowledge Assistant to provide accurate responses and enables HelpDesk Assistant to resolve tickets efficiently while continuously learning and improving over time, ensuring relevance and customer satisfaction.
Try our Easy AI integrated into Easy Redmine, open source project management software, for 30 days to experience the power of RAG!
Frequently asked questions
Related articles

AI in the project manager’s toolbox: Practical help or hype?
Artificial intelligence in project management has mixed both excitement and scepticism. Is AI a game-changer, or is it just another hyped-up tool in the project manager’s toolbox? As AI advances, practical tools like AI Project Status and AI Project Planner from Easy AI offer a look into how AI can enhance the daily work of project managers.

Recognized by Yahoo Finance: Easy Redmine runs the first AI on-premises
For organizations handling sensitive data, choosing between cloud and on-premises solutions is critical. We believe companies shouldn't have to compromise between flexibility and full control over their data and intellectual property. That's why the launch of the first on-premises AI in project management is a major milestone, gaining global attention.

The first AI on-premises in project management software
Artificial intelligence has revolutionized various sectors, and project management is no exception. The emergence of on-premises AI project management software offers unique advantages distinguishing it from cloud-based solutions. Explores the uniqueness of Easy AI on-premises in project management and its benefits.