How AWS and Azure cloud outages cost billions in October 2025

Isn’t the cloud supposed to be rock-solid? In October 2025, both AWS and Azure went down, taking major tools and services with them. On November 18 a bot-management bug caused a multi-hour global outage hitting services like X, ChatGPT and Spotify, while on December 5 a faulty firewall change caused a 25-minute disruption affecting LinkedIn, Zoom and other major sites. If it didn’t hit you, it easily could next time.

Table of contents
Cloud power vs. reliability
Cloud outages expose hidden risks
The true cost of cloud downtime
Why did Jira/Confluence (and lots of other tools) go down?
Practical lessons from cloud outages
Easy Redmine as your reliable hosting choice
Rethink your cloud strategy: Try on-premises or private cloud
TL;DR
Two major cloud outages in October 2025 revealed how fragile modern infrastructure can be, and why teams should rethink relying on a single cloud provider for critical workflows.
Cloud power vs. reliability
When services like Jira Cloud, Confluence, and Jira Data Center go down, the real cause often lies with their hosting infrastructure, which runs on AWS (note: if the company doesn't use a self-hosting solution). These platforms are entirely reliant on third-party cloud providers, and when the cloud stalls, everything else does too.
While cloud computing has revolutionised software scalability and pricing, it has also concentrated the internet’s backbone into the hands of just three providers:
- AWS (Amazon Web Services)
- Microsoft Azure
- Google Cloud
So, when one of them fails, it sends a ripple through a significant portion of the web.
Despite promises of 99,9% uptime, recent outages challenge that narrative. And when systems freeze, businesses depending on these tools are stuck waiting for recovery.
The question isn’t whether the cloud is powerful. It is. The real concern is: how resilient is it?

Cloud services outage in October 2025
Cloud outages expose hidden risks
Cloud improves average reliability and elasticity, but it also centralizes risk in a few above-mentioned platforms. When one has a systemic issue (even in a single region), many unrelated apps break at once. That’s exactly what we saw in October 2025.
The limits of cloud reliability have been tested, reminding many teams just how vulnerable they are when critical services depend on a single infrastructure provider:
- AWS (Oct 20, 2025): AWS suffered a major incident in its US-EAST-1 region that lasted around 15 hours and triggered a chain reaction across other services. The issue, linked to DNS and DynamoDB, didn’t just stay within AWS. It brought down tools like Slack and Atlassian, and even impacted public services like HMRC, along with major banks including Barclays, Lloyds and Bank of Scotland. Downdetector logged thousands of user reports, pointing to just how widespread the disruption was.
- Microsoft Azure (Oct 29, 2025): A global Azure Front Door (AFD) configuration/DNS issue triggered an ~8-hour disruption affecting Azure and Microsoft 365/Xbox; many enterprises and airlines reported outages. At the height of the disruption, over 18,000 users reported issues with Azure and nearly 20,000 with Microsoft 365.
- Cloudflare (Nov 18 2025): Cloudflare suffered a major global outage lasting roughly 3 to 6 hours. The incident disrupted access to high-profile sites and apps including X, ChatGPT, Claude, Discord and Spotify. While Cloudflare did not publish official loss figures, industry benchmarks for enterprise downtime ($5,600–$9,000 per minute and hundreds of thousands to over a million dollars per hour for large organizations) imply aggregate global economic damages in at least the high hundreds of millions of dollars given that thousands of revenue-generating sites were impaired for more than four hours.
- Cloudflare (Dec 5, 2025): Cloudflare suffered a half-hour outage that impacted about 28% of its traffic and briefly took down major sites including LinkedIn, Zoom, Canva, Shopify, etc. The Downdetector website recorded more than 4,500 reports related to Cloudflare after returning online.
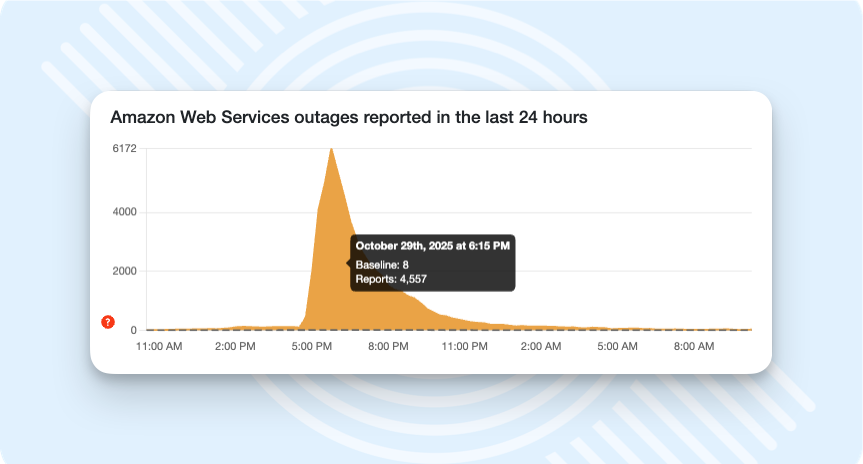
Amazon Web Services outage on October 29th, 2025
Two major cloud outages in one month highlight the growing risk of putting all critical workflows—especially for companies whose critical workflows (Jira/Confluence, CI/CD, auth, payments) all sit on the same cloud, in the same region.
The true cost of cloud downtime
During the AWS outage on 20 October 2025, Downdetector recorded over 17 million user reports from more than 60 countries. A staggering 970% spike compared to a normal day, showing just how far-reaching the disruption was. This made it one of the largest internet outages on record for Downdetector, placing it among the most severe disruptions in recent history.
There is a loss estimate of about $38 million to $581 million, with most outcomes clustering toward the lower end. Analysts and tech press estimated peak losses during the AWS incident at tens of millions of dollars per hour (up to ~$75M/hour at peak). Treat as directional, not exact.
The Microsoft Azure outage before Halloween 2025 wasn’t just a technical hiccup; it came with a massive economic cost. Estimates place the financial impact between $4.8 billion and $16 billion for the eight-hour disruption.
Why did Jira/Confluence (and lots of other tools) go down?
Atlassian Cloud is hosted on AWS, and during the AWS outage, Atlassian’s own status page confirmed that it affected the availability of Confluence and Jira Cloud. So if your company relies on those tools, you were indirectly affected by AWS, even if you don’t use it directly.
In fact, many businesses that say “we don’t use AWS” still felt the impact. Why? Because the tools they do rely on, like identity services, communication platforms, CI/CD pipelines, monitoring tools, and even billing systems, often run on AWS too.
The outage made one thing clear: third-party dependencies run deeper than most teams realise.
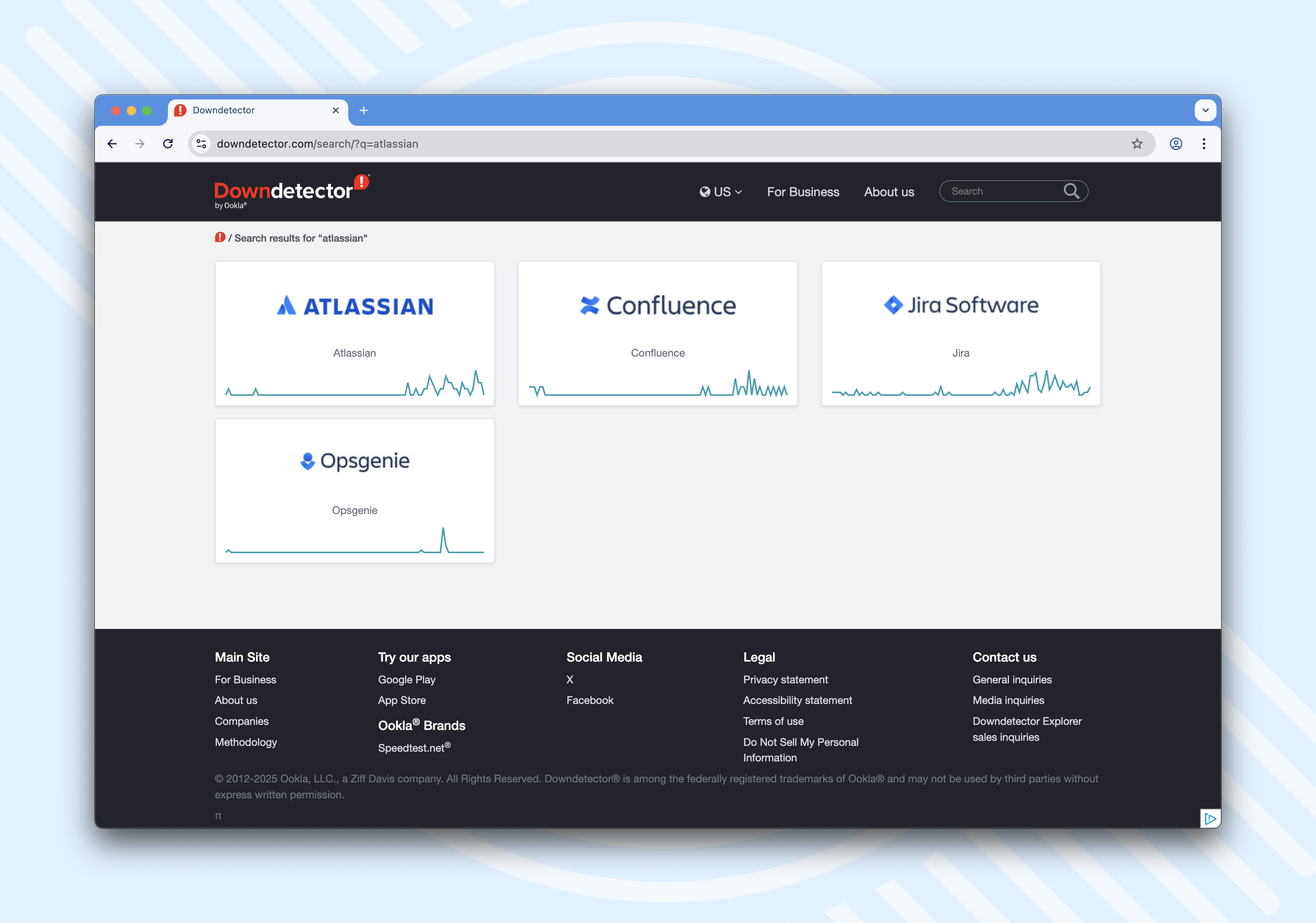
Downdetector: Atlassian services
Practical lessons from cloud outages
The recent AWS and Azure incidents aren’t just headlines. Honestly, they’re reminders to revisit how we design for resilience. Here are some practical takeaways for engineering and ops teams:
1. Know what you really depend on: Start by mapping your business-critical SaaS tools to their underlying cloud providers and regions. For example, if your team uses Jira or Confluence, you’re indirectly dependent on AWS. These should be treated as Tier-1 external dependencies in your business continuity (BCP) and disaster recovery (DR) planning.
2. Design for regional failure: Even if a cloud issue is regional, its effects can ripple globally. That’s why your architecture should include multi-AZ and multi-region failover setups with tested runbooks. If you rely on vendors that only operate in a single region, add fallback measures like read-only modes, graceful degradation, or manual workflows to keep teams working when things go wrong.
3. Don’t put all your trust in one provider: For your most critical systems, consider diversifying your providers. Active-active setups across multiple clouds or cross-cloud DR planning might not be cheap, but as we’ve just seen, the cost of downtime is a real-world ROI baseline.
4. Plan for SaaS outages too: If you rely on tools like Jira or Confluence, have offline or replicated access to your most critical boards and documentation. Define manual communication paths for incidents and pre-approve emergency exceptions (like uploading CSV files manually) so your team isn’t completely stuck.
5. Monitor real signals: Don’t rely solely on vendor SLAs or green lights. Track independent telemetry from platforms like ThousandEyes, Kentik or Cloudflare Radar, and integrate those insights into your alerting and dashboards. That way, you can tell if an issue is just yours or if the whole internet is shaking.
Easy Redmine as your reliable hosting choice
Example: Last month, despite both major cloud outages, 100% of Easy Redmine software maintained over 99.99% availability, which we consider an excellent result. Even more impressive, 99.88% of applications achieved perfect uptime with zero downtime, demonstrating our commitment to reliability when it matters most.

Uptime monitoring in Easy Redmine DevOps dashboard
Easy Redmine users stayed online. With private cloud and on-premises hosting options, Easy Redmine gives you control over your infrastructure. And what is most important, you will get peace of mind when the big clouds fail.
Rethink your cloud strategy: Try on-premises or private cloud
Both outage incidents highlighted critical vulnerabilities in cloud infrastructure concentration, with AWS controlling approximately 32% of the global cloud market and Microsoft Azure at 23%. The back-to-back outages within a single week exposed systemic risks in the digital economy's dependence on a few hyperscale cloud providers.
Don’t be so dependent on centralised clouds; there are other options for running key business infrastructure. Easy Redmine offers both private cloud and on-premises hosting. Easy Redmine on-premises can be a smart choice for companies rethinking their setup, especially as Atlassian plans to end support for Data Center by 2029.
All in all, your team can stay productive even when the giants falter.
Frequently asked questions
Related articles

The end of Jira on-premises: Atlassian Data Center terminates support
Atlassian is pulling the plug on Jira Data Center—and with it, the last on-premises option for Jira users. By 2029, support and updates will be gone entirely. The countdown has started: migrate to the cloud, plan a hybrid setup, or find a true on-premises alternative before the clock runs out.

Less expensive alternative for Jira on-premises
With Jira Server discontinued in 2024, many teams face a choice: accept Atlassian’s Cloud or Data Center terms—or explore more cost-effective alternative!

Knowledge base alternatives: Is Confluence the best choice for you?
An internal knowledge base improves efficiency, communication, and collaboration in companies. Its importance has grown with the rise of Agile methodologies. Atlassian's Confluence is the market leader in central knowledge management, but there are some alternatives that outperform it in certain areas.